CPU jump and high epollwait as throughput increases

CPU jump and high epollwait as throughput increases

|
Dear community,
We have a Flink job which does some parsing, a join and a window. When we increase the load, CPU increases gradually with the throughput. But around 65% CPU, there is suddenly a jump to 98%. The job starts experiencing backpressure and becomes unstable (increasing latency, memory doesn't get cleaned up well anymore). When profiling CPU, we notice that most CPU time is going to epollwait from netty (40-60%). We see this before and after the job becomes unstable. Does this mean it has something to do with network saturation? We also see checkpointing taking around a second at this point (160MB). What are some avenues we can explore to improve this? Thank you for any help provided! Giselle |
Re: CPU jump and high epollwait as throughput increases
|
|
Hi Giselle, could you share the logs of this run with us? They might contain some details. Could you also give us a bit more details about the Flink job and which Flink version you are using? Have you tried using a different netty transport type via `taskmanager.network.netty.transport`? You could set it to `nio`, for example. I am also pulling in Piotr who might know more about problems in the network stack. Cheers, Till On Sat, Nov 7, 2020 at 9:11 AM Giselle van Dongen <[hidden email]> wrote:
|
Re: CPU jump and high epollwait as throughput increases
|
|
Hi Till,
Thank you for the response. The job does the following: reads input from two Kafka topics -> interval joins both streams -> aggregate per second -> write to Kafka The Flink version is 1.11.1. I added the logs of the jobmanager and one of the taskmanagers. Using nio does not seem to improve the situation with our first experiments.
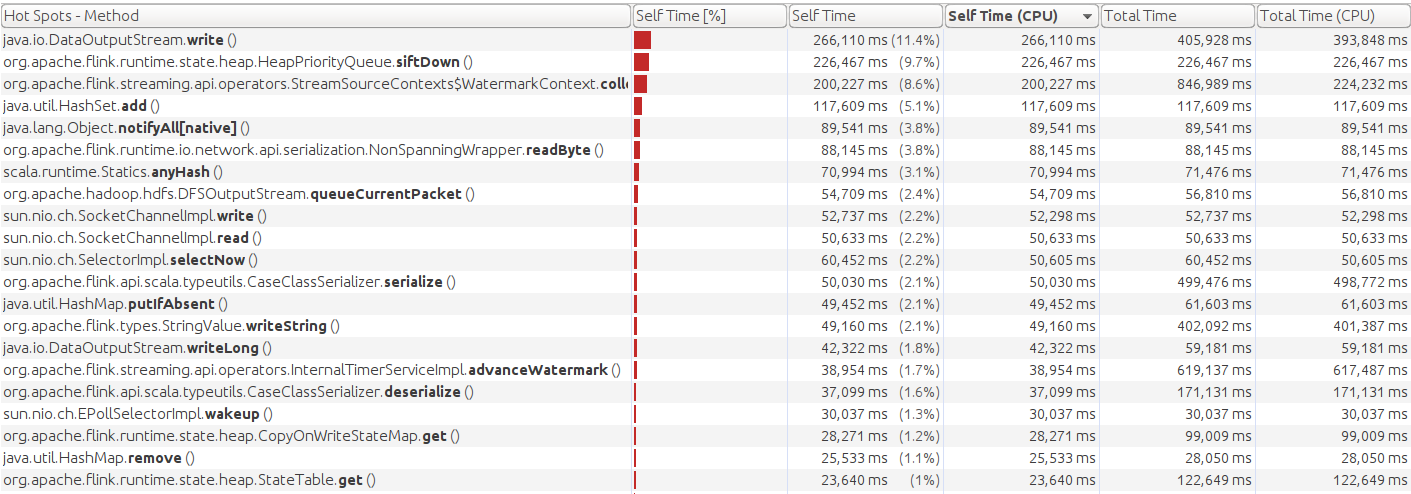
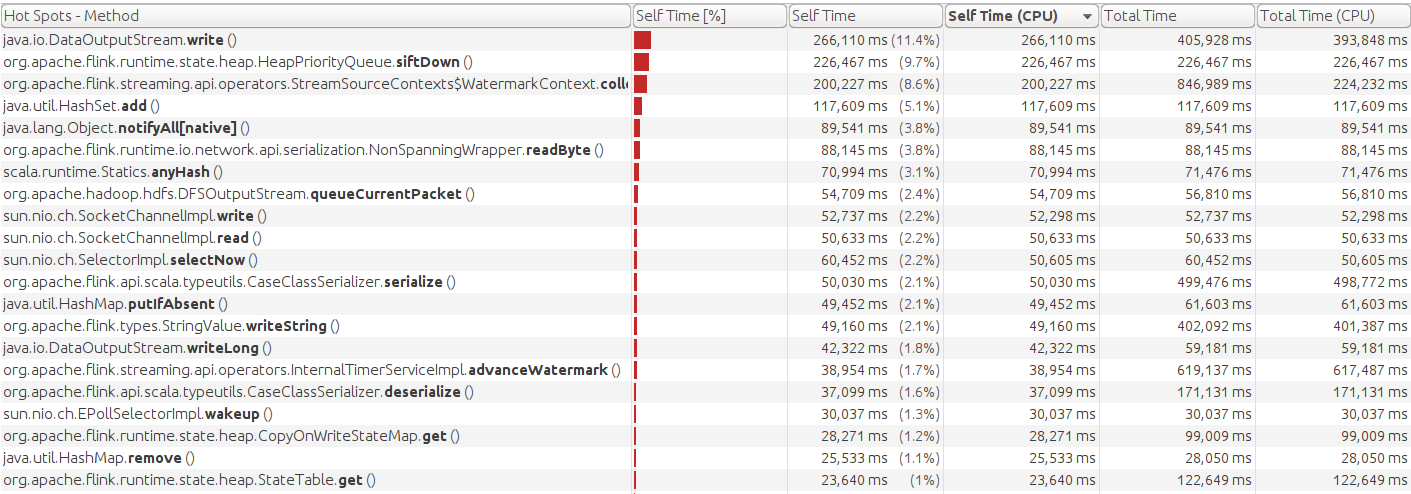
This the CPU profile snapshot with netty:
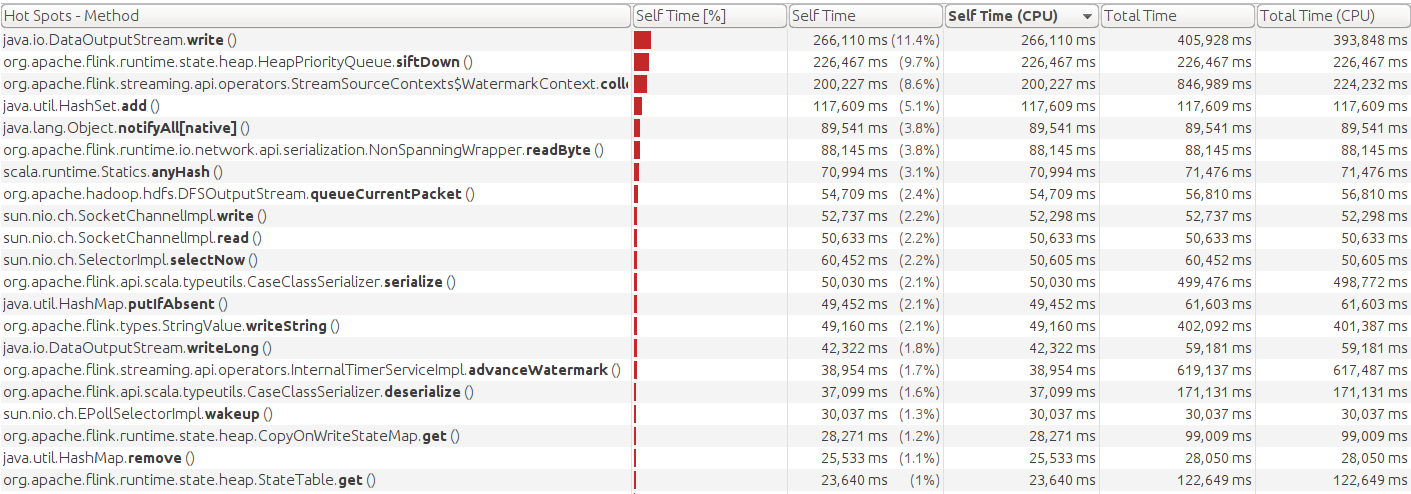
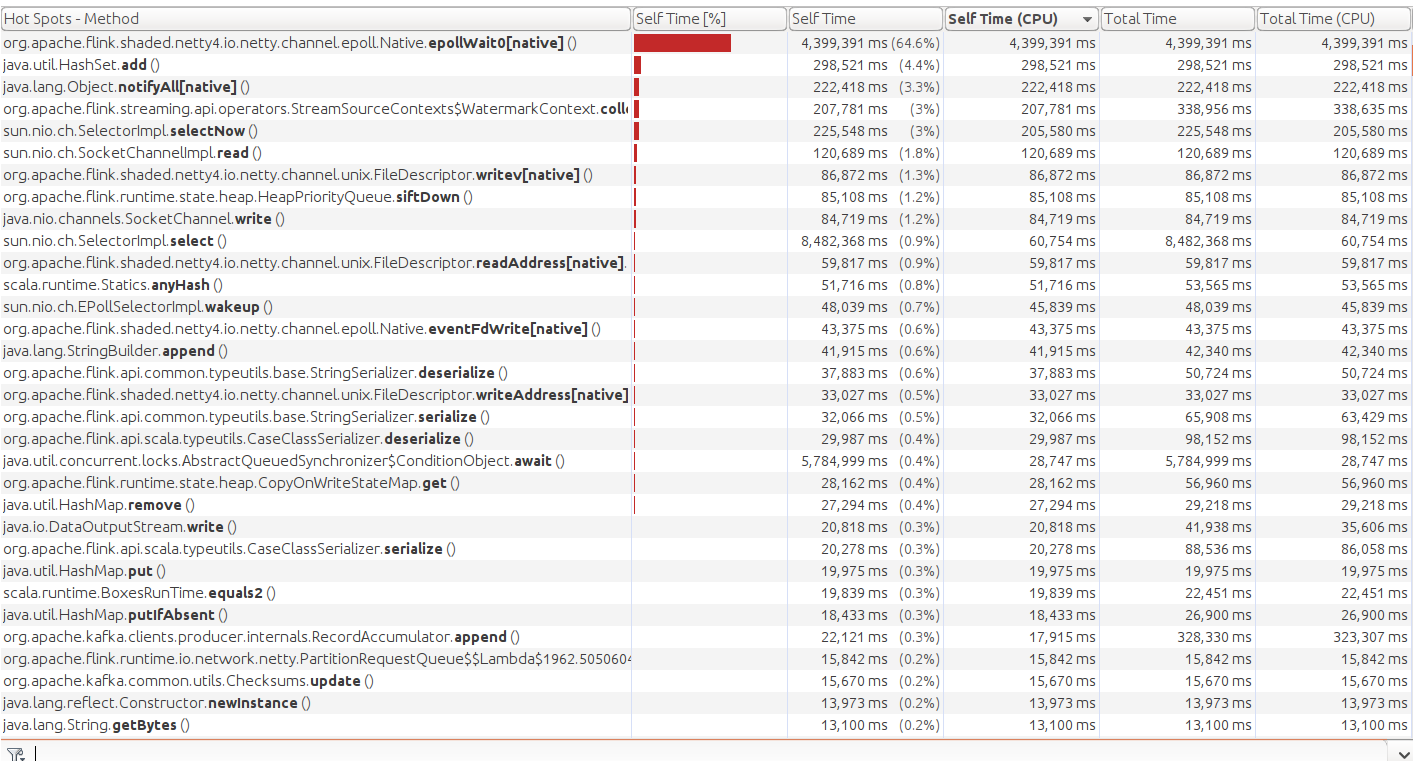 This is the CPU profile with nio at a sustainable throughput level:
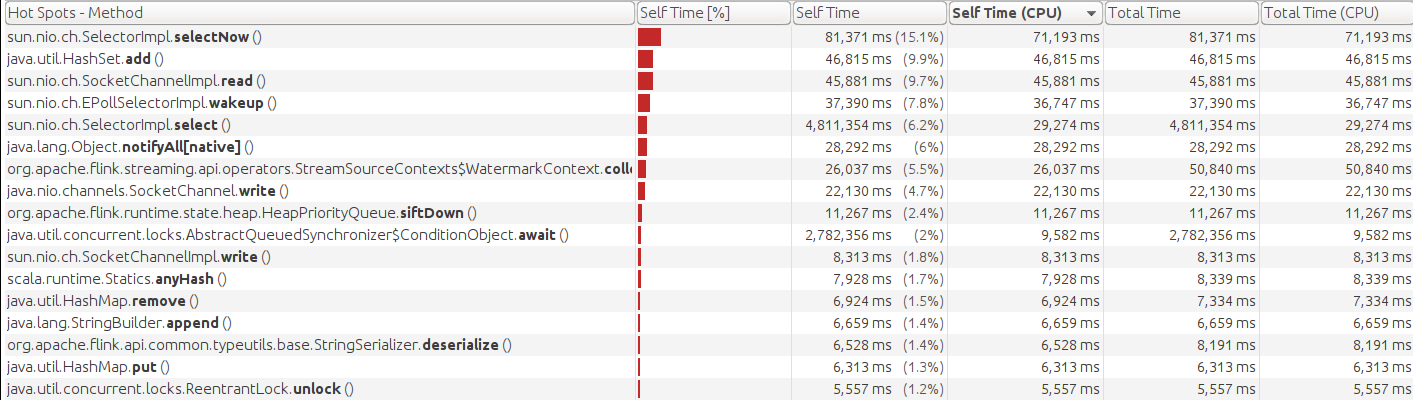
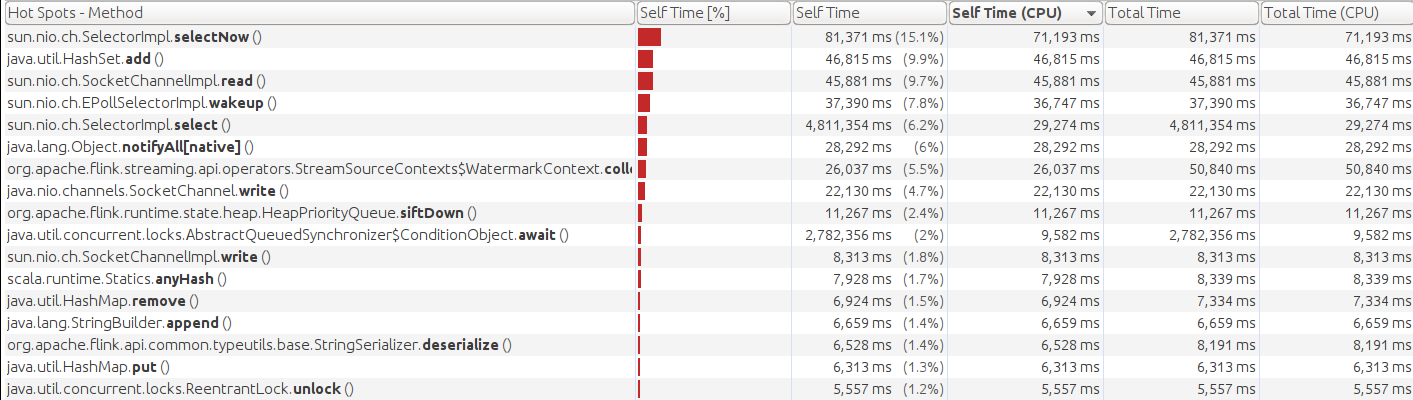
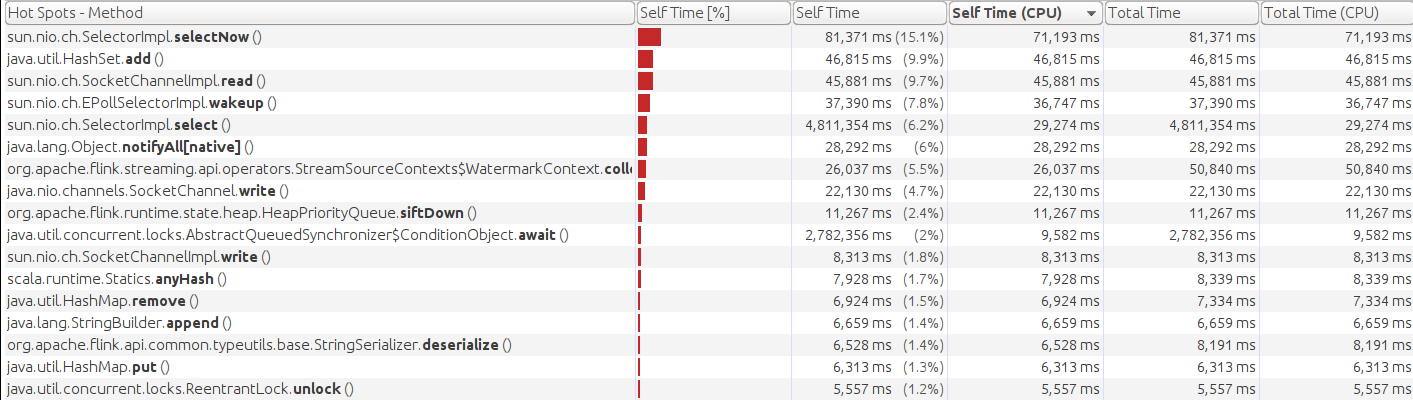 This is the CPU profile with nio at when throughput becomes unsustainable:
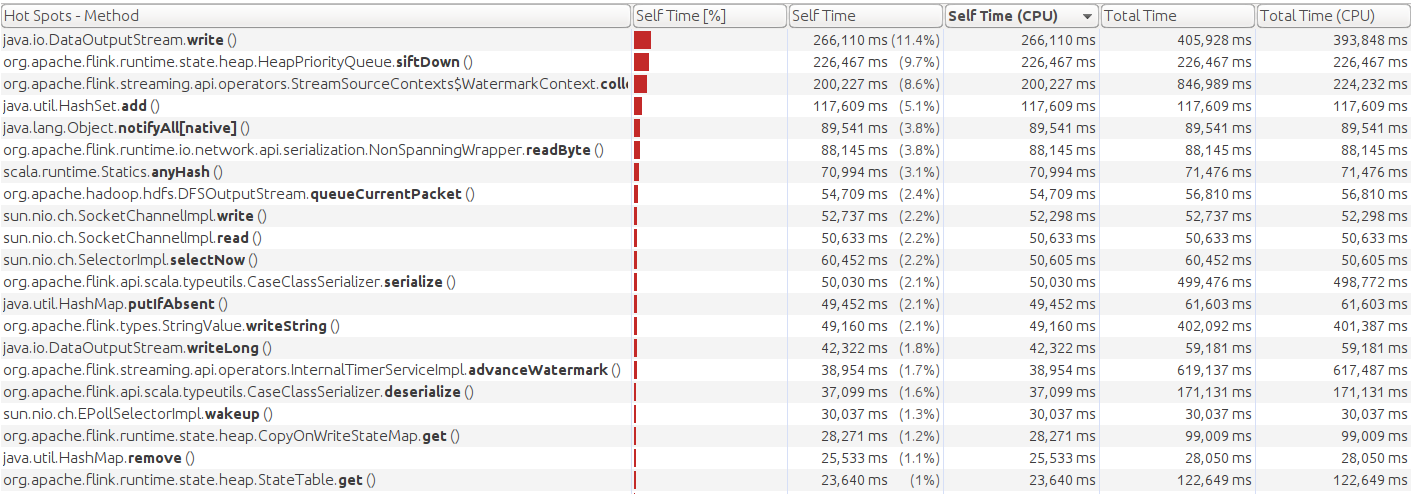 Thank you!
Giselle
From: Till Rohrmann <[hidden email]>
Sent: Saturday, November 7, 2020 4:39:52 PM To: Giselle van Dongen Cc: [hidden email]; pnowojski Subject: Re: CPU jump and high epollwait as throughput increases Hi Giselle,
could you share the logs of this run with us? They might contain some details. Could you also give us a bit more details about the Flink job and which Flink version you are using?
Have you tried using a different netty transport type via `taskmanager.network.netty.transport`? You could set it to `nio`, for example.
I am also pulling in Piotr who might know more about problems in the network stack.
Cheers,
Till
On Sat, Nov 7, 2020 at 9:11 AM Giselle van Dongen <[hidden email]> wrote:
|
Re: CPU jump and high epollwait as throughput increases
|
|
Hi Giselle, I don't see anything suspicious in the logs and I'm also not sure what the profile is supposed to be like. But let's see if we can narrow things down. First of, how many physical/virtual cores do you have per TM and how many TMs? From the logs I see that you have 6 slots per TM, so I suspect 4 TMs. If so, then the odd jump from 66% to ~100% may be connected with CPU. Could you try to set slots per TM exactly to (physical) cores if you haven't already? Secondly, how did you get the CPU profiles? It looks like visualvm. Did you remotely connect to one TM? Did you sample or did you instrument? If the former, make sure you have the lowest possible interval or even better try out instrumentation. Best, Arvid On Sun, Nov 8, 2020 at 1:22 PM Giselle van Dongen <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |
Re: CPU jump and high epollwait as throughput increases
|
|
Arvid,
We have 2 TMs and we set parallelism of the job to 12 (6 CPUs and 6 taskslots per taskmanager). So indeed the number of slots is equal to the physical cores.
I indeed use VisualVM and connect remotely to the cluster and the screenshots came from CPU sampling. I have been taking a more thorough look at the other metrics. Both buffers.outPoolUsage and buffers.inPoolUsage are high for the interval join and low for the other stages. It seems like the join is very heavy on CPU and checkpointing. Would this lead us closer to an explanation for the jump in CPU?
I checked whether HDFS was the bottleneck by switching to S3 but this caused even worse performance. The duration size of checkpoints quickly increases to multiple GBs.
Regards, Giselle From: Arvid Heise <[hidden email]>
Sent: Monday, November 9, 2020 7:59:43 PM To: Giselle van Dongen Cc: Till Rohrmann; [hidden email]; pnowojski Subject: Re: CPU jump and high epollwait as throughput increases Hi Giselle,
I don't see anything suspicious in the logs and I'm also not sure what the profile is supposed to be like. But let's see if we can narrow things down.
First of, how many physical/virtual cores do you have per TM and how many TMs? From the logs I see that you have 6 slots per TM, so I suspect 4 TMs. If so, then the odd jump from 66% to ~100% may be connected with CPU. Could you try to set slots per TM
exactly to (physical) cores if you haven't already?
Secondly, how did you get the CPU profiles? It looks like visualvm. Did you remotely connect to one TM? Did you sample or did you instrument? If the former, make sure you have the lowest possible interval or even better try out instrumentation.
Best,
Arvid
On Sun, Nov 8, 2020 at 1:22 PM Giselle van Dongen <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |

Re: CPU jump and high epollwait as throughput increases
|
|
Hi Giselle, pool usage definitively indicates that the join is the bottleneck. Is that also visible in the backpressure metrics? Could you double-check whether the CPU usage looks the same if you use instrumentation instead of sampling. That should give a clearer indication on the sleep time. And lastly, do your machines have 6 physical cores or is hyperthreading involved? On Tue, Nov 17, 2020 at 9:09 AM Giselle van Dongen <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |
| Free forum by Nabble | Edit this page |