Application cluster - Best Practice

Application cluster - Best Practice

|
Hey All,
I'm running an application cluster(Flink 1.11.1) on top of Kubernetes(currently running locally using docker-desktop). deployed via terraform module. (2 task managers)
I followed the following instruction(well written)
I have successfully executed the batch job. Kubernetes job(marked as completed)
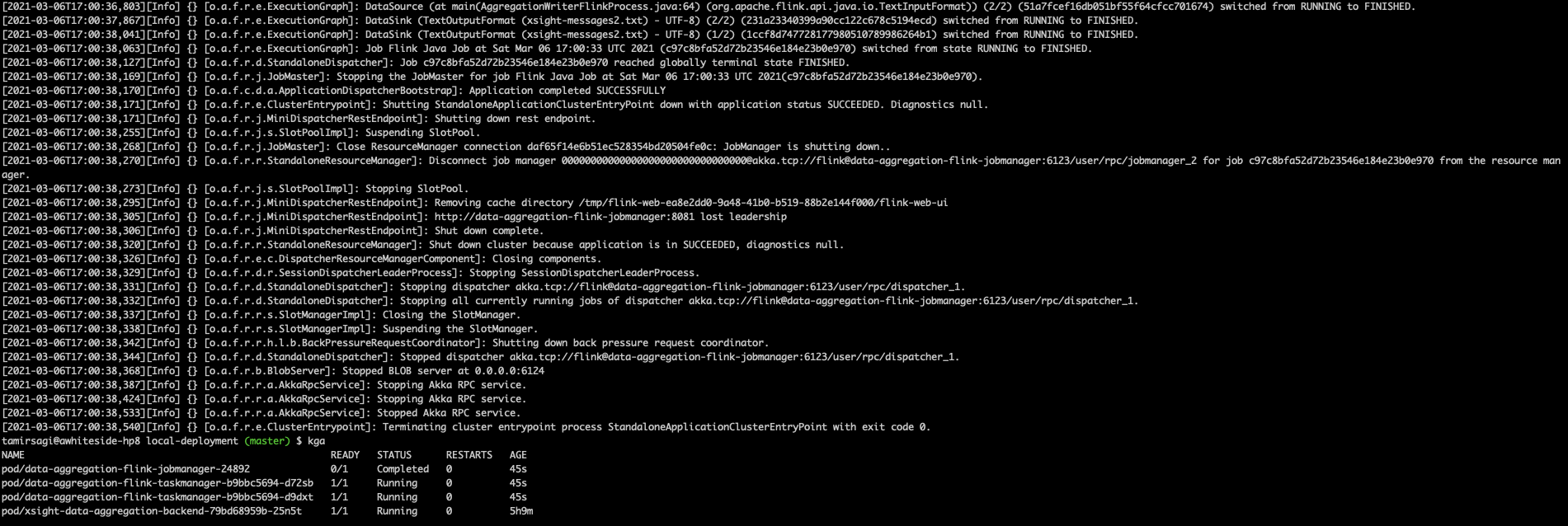 I was reading the following article https://flink.apache.org/news/2020/07/14/application-mode.html
I have several questions
Thanks,
Tamir.

|
Re: Application cluster - Best Practice
|
|
Hi Tamir, 1. How you start a cluster in application mode depends on how you deploy Flink. If you want to use Flink's standalone application mode, then you have to deploy a new cluster for every job you want to run [1, 2, 3]. What a standalone application cluster needs is the user code jar and a pointer which class to run. So if you want to deploy a standalone cluster on Docker or Kubernetes, then you either add the user code to your image, mount it as a volume or specify an init container (K8s case) to download the user code jar from somewhere. If you want to deploy on K8s and are able to use Flink's native integration (meaning that Flink can talk with the K8s cluster), you can also use the client to submit a new application cluster [4]. But also here, you have to make the user code available to your container in some way. 2. If you deploy your application cluster in standalone mode, then Flink won't automatically terminate the TaskManagers. This only works when using one of Flink's active deployments (K8s or Yarn). Hence, you either have to wait for the registration timeout of the TaskManager or stop them explicitly. 3. No, TaskManagers don't have to stay alive. The fact that they stayed alive is caused by the fact that you deployed Flink in standalone mode where Flink cannot start and stop TaskManagers. Cheers, Till On Sat, Mar 6, 2021 at 6:16 PM Tamir Sagi <[hidden email]> wrote:
|
Re: Application cluster - Best Practice
|
|
Hey Till,
Thank you for responding.
I've already read the link you send , but they are not enough , they don't provide a good solution for production.
Standalone-Kubernetes is not a good approach for production for 3 main reasons(In my opinion):
Native k8s is the right approach since it terminates all dynamic resources, however the documentation shows only a deployment via Flink CLI, which again not a good practice in production
Another solution is to use Kubernetes Operation(i.e https://github.com/wangyang0918/flink-native-k8s-operator) ,however, the operator expects CRDs, which defined by yaml
file + triggering new Flink app is done by yaml files.
Unfortunately, the documentation doesn't elaborate much about the Flink Client.
After digging and debugging the operation lib above, I found out that Flink client can deploy an application cluster.
Here is a simple Program that creates an application cluster
with dynamic resources allocation (Using Flink Client & Flink Kubernetes client) in Java
Dependencies (i.e flink.version=1.12.1, scala.binary.version=2.12)
<dependency>Java Code: Where the getEffectiveConfig() returns a Configuration Object. represents a flink-conf.yaml file with all necessary parameters@Log4j2 For example: if specific configurations for TM or JM are needed, then you can configure them like thatConfiguration effectiveConfig = new Configuration(); //you can load from file: GlobalConfiguration.loadConfiguration(<path>); effectiveConfig.setString(JobManagerOptions.TOTAL_PROCESS_MEMORY.key(), "1024m");
If the application runs outside K8S it might throw an error indicating the pod failed to find the REST endpoint (it looks for k8s format <cluster-name>-rest.<namespace>) - but the cluster will be deployed anyway.
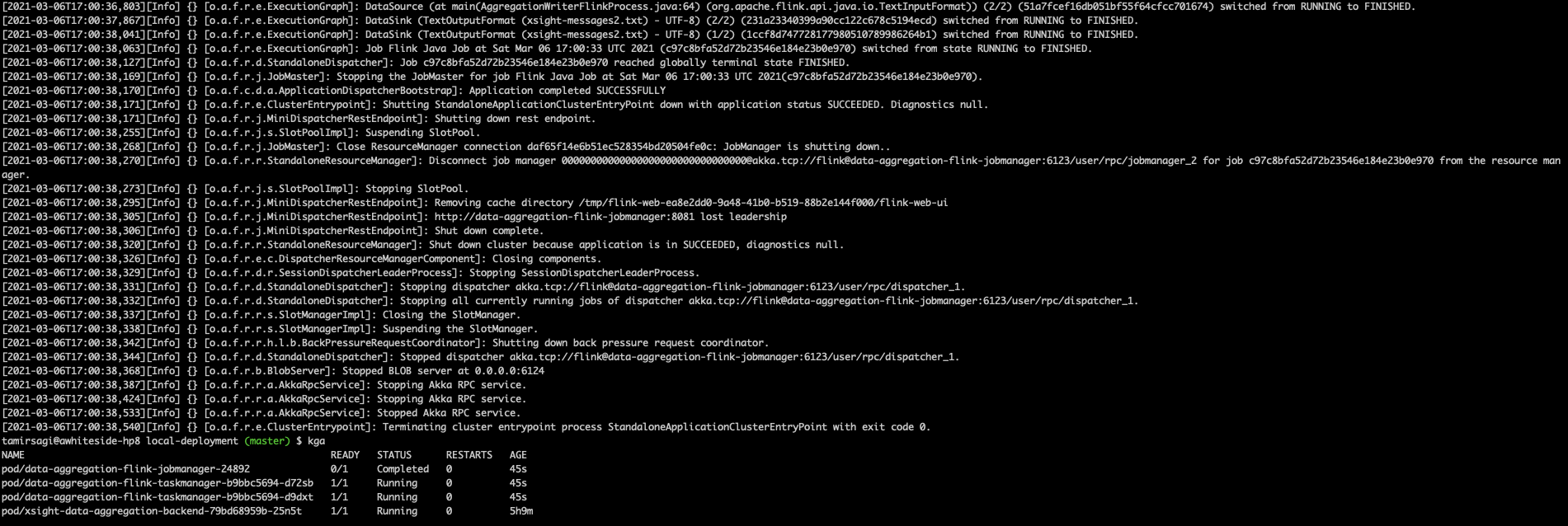
I deployed the application on k8s (docker-desktop)
Docker file for the program above (config is the local Kubernetes credentials file located in ~/.kube/config) I copied it to the project dir.
FROM openjdk:11-jdk-slim-buster Hope that helps,
Tamir.
From: Till Rohrmann <[hidden email]>
Sent: Thursday, March 11, 2021 3:40 PM To: Tamir Sagi <[hidden email]> Cc: [hidden email] <[hidden email]> Subject: Re: Application cluster - Best Practice
Hi Tamir,
1. How you start a cluster in application mode depends on how you deploy Flink. If you want to use Flink's standalone application mode, then you have to deploy a new cluster for every job you want to run [1, 2, 3]. What a standalone application cluster
needs is the user code jar and a pointer which class to run. So if you want to deploy a standalone cluster on Docker or Kubernetes, then you either add the user code to your image, mount it as a volume or specify an init container (K8s case) to download the
user code jar from somewhere.
If you want to deploy on K8s and are able to use Flink's native integration (meaning that Flink can talk with the K8s cluster), you can also use the client to submit a new application cluster [4]. But also here, you have to make the user code available
to your container in some way.
2. If you deploy your application cluster in standalone mode, then Flink won't automatically terminate the TaskManagers. This only works when using one of Flink's active deployments (K8s or Yarn). Hence, you either have to wait for the registration timeout
of the TaskManager or stop them explicitly.
3. No, TaskManagers don't have to stay alive. The fact that they stayed alive is caused by the fact that you deployed Flink in standalone mode where Flink cannot start and stop TaskManagers.
Cheers,
Till
On Sat, Mar 6, 2021 at 6:16 PM Tamir Sagi <[hidden email]> wrote:

|
Re: Application cluster - Best Practice
|
|
What the Flink client does for you when starting an application mode cluster in native K8s mode is to generate the K8s job specification and to submit it to the K8s cluster. Hence, you can also do it yourself if you prefer to manage the K8s resources directly. Writing your own client should also work but is of course more work. Cheers, Till On Thu, Mar 11, 2021 at 3:49 PM Tamir Sagi <[hidden email]> wrote:
|
Re: Application cluster - Best Practice
|
|
Hey Till,
You are right.
I'm new to Flink, I was looking for a Java way to deploy an application cluster. I first tried the standalone approach and changed to native (although the
official documents specify that application mode is more suitable for production , they show only the CLI way).
I encountered the k8s operator (Which provided me a good direction) but was unnecessary Since we don't want to deal with custom resources and manage K8S resources ourselves.
Hence, as I showed, I wrote a small program that deploys an application cluster(Using Flink client & Flink Kubernetes client - which uses the
fabric8io-kubernetes-client under the hood) for others who will encounter that post.
Cheers mate,
Tamir.

From: Till Rohrmann <[hidden email]>
Sent: Thursday, March 11, 2021 7:13 PM To: Tamir Sagi <[hidden email]> Cc: [hidden email] <[hidden email]> Subject: Re: Application cluster - Best Practice
What the Flink client does for you when starting an application mode cluster in native K8s mode is to generate the K8s job specification and to submit it to the K8s cluster. Hence, you can also do it yourself if you prefer to manage the K8s resources
directly. Writing your own client should also work but is of course more work.
Cheers,
Till
On Thu, Mar 11, 2021 at 3:49 PM Tamir Sagi <[hidden email]> wrote:
|
|
|
Hi Tamir, Thanks for sharing the information. I think you are right. If you dive into the code implementation of flink-native-k8s-operator[1], they are just same. [hidden email] Do you think it is reasonable to make "ApplicationDeployer" interface as public? Then I believe it will be great easier to integrate with deployer systems. Best, Yang Tamir Sagi <[hidden email]> 于2021年3月12日周五 上午3:56写道:
|
Re: Application cluster - Best Practice
|
|
Hey Yang,
The operator gave me a good lead by "revealing" that Application Deployer does exist and there is a way to do what I was looking for programmatically.
Just a quick note, the operator uses the same Flink methods internally to deploy the application cluster but also provide a way to submit jobs via CRDs(which is not a good approach for our needs).
IMHO I think it's important to add such Application Deployer example into the documents.
Best,
Tamir.

From: Yang Wang <[hidden email]>
Sent: Monday, March 15, 2021 11:29 AM To: Tamir Sagi <[hidden email]> Cc: Till Rohrmann <[hidden email]>; [hidden email] <[hidden email]> Subject: Re: Application cluster - Best Practice
Hi Tamir,
Thanks for sharing the information.
I think you are right. If you dive into the code implementation of flink-native-k8s-operator[1], they are just same.
[hidden email] Do you think it is reasonable to make "ApplicationDeployer" interface as public? Then I believe
it will be great easier to integrate with deployer systems.
Best,
Yang
Tamir Sagi <[hidden email]> 于2021年3月12日周五 上午3:56写道:
|
|
|
I have created a ticket FLINK-21807[1] to track this requirement. Best, Yang Tamir Sagi <[hidden email]> 于2021年3月16日周二 上午1:11写道:
|
Re: Application cluster - Best Practice
|
|
Concerning making the ApplicationDeployer interface public, I think we need a community discussion. At the moment this interface is marked as internal. However, I can see the benefits of exposing this interface and respective implementation. I guess the main question is up to which level do we want to make things public. Public interfaces cannot be changed easily and, hence, come with a higher price tag. In any case, Tamir you can already use the ApplicationDeployer. You just should be aware that this interface might be changed when upgrading Flink versions. Cheers, Till On Tue, Mar 16, 2021 at 6:10 AM Yang Wang <[hidden email]> wrote:
|
Re: Application cluster - Best Practice
|
|
Hey Till,
Since the client provides a way to instantiate the ApplicationClusterDeployer its already considered 'public'.
IMHO, as long as it's achievable, it must be added to the documentations, because they are incomplete.
Right now, we can proceed with the ApplicationDeployer. I really hope that in case the interface or the ApplicationClusterDeployer modifier will change , we will be provided with an alternative.
Best,
Tamir.

From: Till Rohrmann <[hidden email]>
Sent: Wednesday, March 17, 2021 2:29 PM To: Yang Wang <[hidden email]> Cc: Tamir Sagi <[hidden email]>; [hidden email] <[hidden email]> Subject: Re: Application cluster - Best Practice
Concerning making the ApplicationDeployer interface public, I think we need a community discussion. At the moment this interface is marked as internal. However, I can see the benefits of exposing this interface and respective implementation.
I guess the main question is up to which level do we want to make things public. Public interfaces cannot be changed easily and, hence, come with a higher price tag.
In any case, Tamir you can already use the ApplicationDeployer. You just should be aware that this interface might be changed when upgrading Flink versions.
Cheers,
Till
On Tue, Mar 16, 2021 at 6:10 AM Yang Wang <[hidden email]> wrote:
|
Re: Application cluster - Best Practice
|
|
The ApplicationClusterDeployer is not
considered public; it is explicitly marked as @Internal.
Just because the constructor is
accessible from a jar does not imply in any way that it should be
used by users or that any guarantees regarding it's API stability
are provided.
On 3/17/2021 1:56 PM, Tamir Sagi wrote:
|
Re: Application cluster - Best Practice
|
|
Hey Chesnay

From: Chesnay Schepler <[hidden email]>
Sent: Wednesday, March 17, 2021 3:15 PM To: Tamir Sagi <[hidden email]>; Till Rohrmann <[hidden email]>; Yang Wang <[hidden email]> Cc: [hidden email] <[hidden email]> Subject: Re: Application cluster - Best Practice
The ApplicationClusterDeployer is not considered public; it is explicitly marked as @Internal.
Just because the constructor is accessible from a jar does not imply in any way that it should be used by users or that any guarantees regarding it's API stability are provided.
On 3/17/2021 1:56 PM, Tamir Sagi wrote:
|
Re: Application cluster - Best Practice
|
|
Hi Tamir, one big consideration with making things public is that the community cannot change it easily because users expect that these interfaces are stable. This translates effectively to higher maintenance costs for the community. Cheers, Till On Wed, Mar 17, 2021 at 3:13 PM Tamir Sagi <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |