About nodes number on Flink


|
Hello,
I'm developing a Flink toy-application on my local machine before to deploy the real one on a real cluster. Now I have to determine how many nodes I need to set the cluster. I already read these documents: jobs and scheduling programming model parallelism But I'm still a bit confused about how many nodes I have to consider to execute my application. For example if I have the following code (from the doc):  - This means that operations "on same line" are executed on same node? (It sounds a bit strange to me) Some confirms: - If the answer to previous question is yes and if I set parallelism to '1' I can establish how many nodes I need counting how many operations I have to perform ? - If I set parallelism to 'N' but I have less than 'N' nodes available Flink automatically scales the elaboration on available nodes? My throughput and data load is not relevant I think, it is not heavy. |
|
|
Hi Andrea,
the number of nodes usually depends on the work that you do within your Functions. E.g. if you have a computation intensive machine learning library in a MapFunction and takes 10 seconds per element, it might make sense to paralellize this in order to increase your throughput. Or if you have to save state of several GBs per key which would not fit on one machine. Flink does not only parallelize per node but also per "slot". If you start your application with a parallelism of 2 (and have not configured custom parallelisms per operator), you will have two pipelines that process elements (so two MapFunctions are running in parallel one in each pipeline). 2 slots are occupied in this case. There are operations (like keyBy) that break this pipeline and repartition your data. If you want to run operators in separate slots you can start a new chain (see here: https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/datastream_api.html#task-chaining-and-resource-groups) If you set parallelism to 'N' but I have less than 'N' SLOTS available, you cannot execute the job. I hope my explanation helps. Regards, Timo Am 22.06.17 um 16:54 schrieb AndreaKinn: > Hello, > I'm developing a Flink toy-application on my local machine before to deploy > the real one on a real cluster. > Now I have to determine how many nodes I need to set the cluster. > > I already read these documents: > jobs and scheduling > <https://ci.apache.org/projects/flink/flink-docs-release-1.3/internals/job_scheduling.html> > programming model > <https://ci.apache.org/projects/flink/flink-docs-release-1.2/concepts/programming-model.html> > parallelism > <https://flink.apache.org/faq.html#what-is-the-parallelism-how-do-i-set-it> > > But I'm still a bit confused about how many nodes I have to consider to > execute my application. > > For example if I have the following code (from the doc): > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13927/Screen_Shot_2017-06-22_at_16.png> > > - This means that operations "on same line" are executed on same node? (It > sounds a bit strange to me) > > Some confirms: > - If the answer to previous question is yes and if I set parallelism to '1' > I can establish how many nodes I need counting how many operations I have to > perform ? > - If I set parallelism to 'N' but I have less than 'N' nodes available Flink > automatically scales the elaboration on available nodes? > > My throughput and data load is not relevant I think, it is not heavy. > > > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/About-nodes-number-on-Flink-tp13927.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
|
|
Hi Timo, thanks for your answer.
I think my elaboration are not too much heavy so I imagine I will have no advantages to "parallelize" streams. In my mind I have this pipeline: 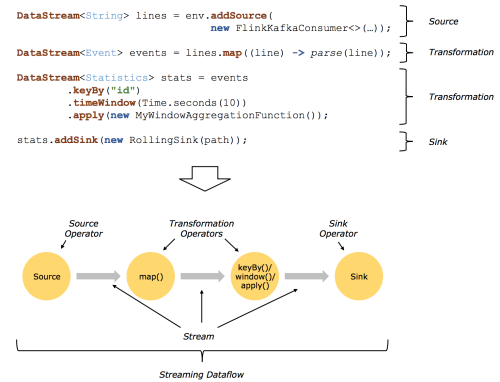 And this is exactly what I want develop: a need a pipeline where a node runs fixed operation and forward elaborated data to the next and so on. How can I obtain this? If I understand "chaining" considers the possibility of execute multiple operations on same thread to improve performance. |
|
|
If you really what to run one operation per node. You start 1
TaskManager with 1 slot on every node. For each operation you set a new chain and a new slot sharing group. Timo Am 23.06.17 um 15:03 schrieb AndreaKinn: > Hi Timo, thanks for your answer. > I think my elaboration are not too much heavy so I imagine I will have no > advantages to "parallelize" streams. > > In my mind I have this pipeline: > > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n13969/Screen_Shot_2017-06-22_at_19.png> > > And this is exactly what I want develop: a need a pipeline where a node runs > fixed operation and forward elaborated data to the next and so on. How can I > obtain this? > > If I understand "chaining" considers the possibility of execute multiple > operations on same thread to improve performance. > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/About-nodes-number-on-Flink-tp13927p13969.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |